创建虚拟机
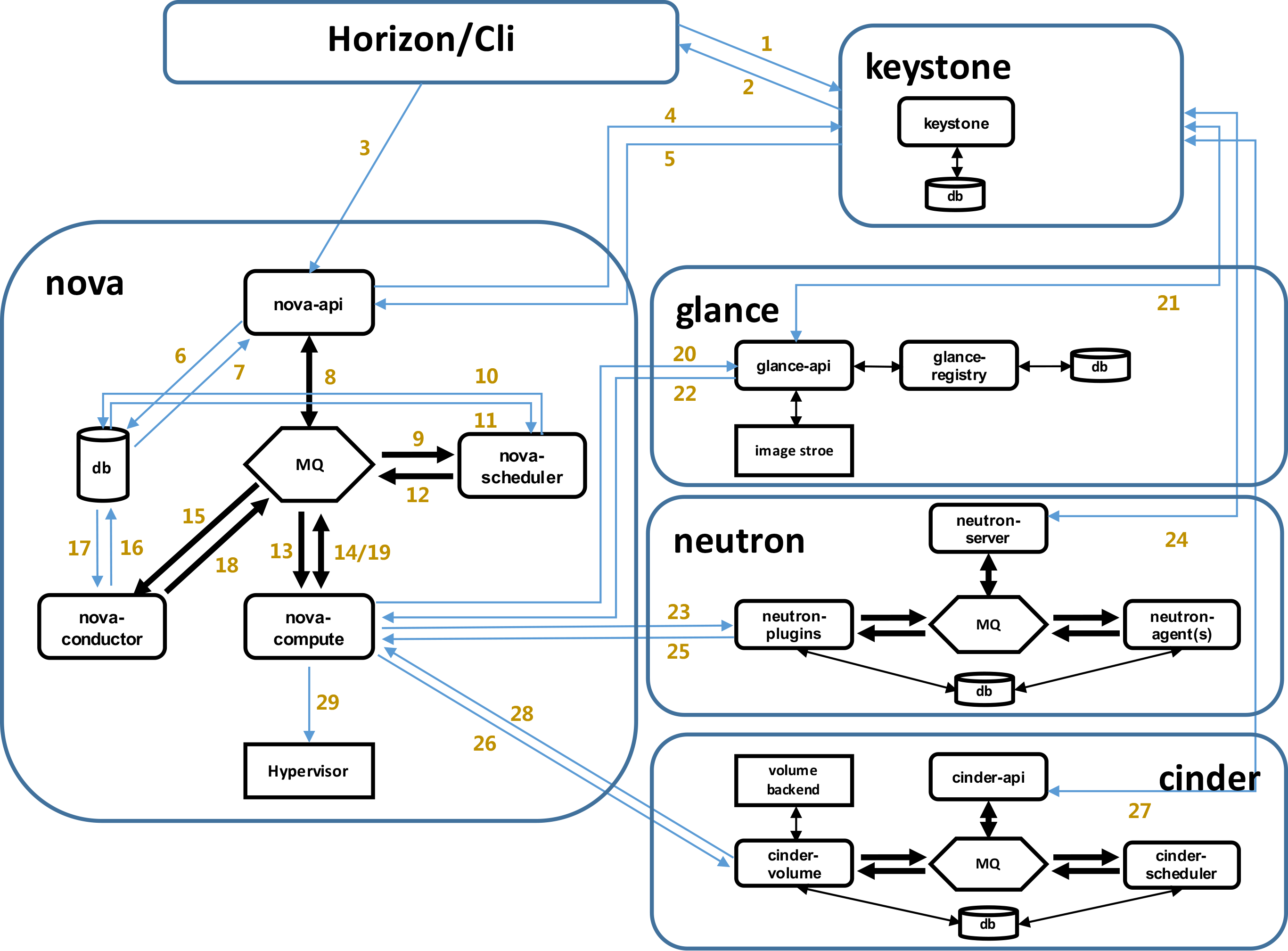
1、界面或命令行通过RESTful API向keystone获取认证信息。
2、keystone通过用户请求认证信息,并生成auth-token返回给对应的认证请求。
3、界面或命令行通过RESTful API向nova-api发送一个boot instance的请求(携带auth-token)。
4、nova-api接受请求后向keystone发送认证请求,查看token是否为有效用户和token。
5、keystone验证token是否有效,如有效则返回有效的认证和对应的角色(注:有些操作需要有角色权限才能操作)。
6、通过认证后nova-api和数据库通讯。
7、初始化新建虚拟机的数据库记录。
8、nova-api通过rpc.call向nova-scheduler请求是否有创建虚拟机的资源(Host ID)。
9、nova-scheduler进程侦听消息队列,获取nova-api的请求。
10、nova-scheduler通过查询nova数据库中计算资源的情况,并通过调度算法计算符合虚拟机创建需要的主机。
11、对于有符合虚拟机创建的主机,nova-scheduler更新数据库中虚拟机对应的物理主机信息。
12、nova-scheduler通过rpc.cast向nova-compute发送对应的创建虚拟机请求的消息。
13、nova-compute会从对应的消息队列中获取创建虚拟机请求的消息。
14、nova-compute通过rpc.call向nova-conductor请求获取虚拟机消息。(Flavor)
15、nova-conductor从消息队队列中拿到nova-compute请求消息。
16、nova-conductor根据消息查询虚拟机对应的信息。
17、nova-conductor从数据库中获得虚拟机对应信息。
18、nova-conductor把虚拟机信息通过消息的方式发送到消息队列中。
19、nova-compute从对应的消息队列中获取虚拟机信息消息。
20、nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求glance-api获取创建虚拟机所需要镜像。
21、glance-api向keystone认证token是否有效,并返回验证结果。
22、token验证通过,nova-compute获得虚拟机镜像信息(URL)。
23、nova-compute通过keystone的RESTfull API拿到认证k的token,并通过HTTP请求neutron-server获取创建虚拟机所需要的网络信息。
24、neutron-server向keystone认证token是否有效,并返回验证结果。
25、token验证通过,nova-compute获得虚拟机网络信息。
26、nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求cinder-api获取创建虚拟机所需要的持久化存储信息。
27、cinder-api向keystone认证token是否有效,并返回验证结果。
28、token验证通过,nova-compute获得虚拟机持久化存储信息。
29、nova-compute根据instance的信息调用配置的虚拟化驱动来创建虚拟机。
以Nova为例,nova/compute目录并不是一定在nova-compute节点上运行,而主要是和compute相关(虚拟机操作相关)的功能实现,同样的,scheduler目录代码并不全在scheduler服务节点运行,但主要是和调度相关的代码。不过目录结构遵循一定的规律。
通常一个OpenStack项目的代码目录都会包含api.py、rpcapi.py、manager.py,这三个是最重要的模块。
api.py: 通常是供其它组件调用的封装库。换句话说,该模块通常并不会由本模块调用。比如compute目录的api.py,通常由nova-api服务的controller调用。可以简单认为是供其他服务调用的sdk。rpcapi.py:这个是RPC请求的封装,或者说是RPC封装的client端,该模块封装了RPC请求调用。manager.py: 这个才是真正服务的功能实现,也是RPC的server端,即处理RPC请求的入口,实现的方法通常和rpcapi实现的方法一一对应。
关机流程
API节点 nova-api接收用户请求 -> nova-api调用compute/api.py -> compute/api调用compute/rpcapi.py -> rpcapi.py向目标计算节点发起stop_instance()RPC请求 计算节点 收到stop_instance()请求 -> 调用compute/manager.py的callback方法stop_instance() -> 调用libvirt关机虚拟机
前面提到OpenStack项目的目录结构是按照功能划分的,而不是服务组件,因此并不是所有的目录都能有对应的组件。仍以Nova为例:
nova/cmd:这是服务的启动脚本,即所有服务的main函数。看服务怎么初始化,就从这里开始。nova/db: 封装数据库访问,目前支持的driver为sqlalchemy。nova/conf:Nova所有配置项声明都放在这个目录。nova/locale: 本地化处理。nova/image: 封装Glance接口。nova/network: 封装Neutron接口。nova/volume: 封装Cinder接口。nova/virt: 这是支持的所有虚拟化驱动实现,即compute driver实现,主流的如libvirt、hyperv、ironic、vmwareapi等。nova/objects: 对象模型,封装了所有Nova对象的CURD操作,相对以前直接调用db的model更安全,并且支持版本控制。nova/policies: API policy集合。nova/tests: 测试代码,如单元测试、功能测试。nova/hacking: Nova代码规范定义的一些规则。
nova –debug boot –image 81e58b1a-4732-4255-b4f8-c844430485d2 –flavor 1 yikun
controller的index方法对应list操作、show方法对应get操作、create对应创建操作、delete对应删除操作、update对应更新操作等。
openstack-nova-compute.service 两个职责,其一,是守护进程,负责基于各种虚拟化技术Hypervisior实现创建和终止虚拟机;其二,整合了计算资源CPU,存储,网络三类资源部署管理虚拟机,实现计算能力的交付。
Cell V2的设计思想是,由API、Super Conductor去访问上层的全局数据库(nova_api数据库),而底下的cell中的组件,只需要关心cell中的逻辑即可
- 首先,api中进行第一次Quota检测,主要方法就是收集地下各个cell数据库中的资源信息,然后和api数据库中的quota上限进行对比。例如,一个用户可以创建10个虚拟机,在cell1中有2个,cell2中有7个,再创建一个虚拟机时,会搜集cell1和cell2中的虚拟机个数之和(9个),然后加上变化(新增一个),与总配额进行比较。
- 二次检测(cell v2在super conductor里做)。由于在并发场景下,可能出现同时检测发现满足,之后进行创建,就会造成配额的超分,针对这个问题,社区目前给出的方案是,在创建虚拟机记录之后,再进行recheck,如果发现超额了,会将超额分配的虚拟机标记为ERROR,不再继续往下走了。
在Cell v2场景,虚拟机的创建记录已经需要写入的子cell中,因此,conductor需要做的事,包括一下几个步骤:
- 进行调度,选出host。
- 根据host,通过host_mappings找到对应的cell
- 在对应的cell db中创建虚拟机记录,并且记录instances_mappings信息
- 通过cell_mappings来查找对应的cell的mq,然后投递到对应的cell中的compute
完成这些操作时,需要牵扯到3个关键的数据结构,我们来简单的看一下:
- host_mappings:记录了host和cell的映射信息
- instances_mappings:记录了虚拟机和cell的映射信息
- cell_mappings:记录了cell和cell对应的mq的映射信息
与Cell v1不太相同,在目前的设计中,认为scheduler能看到的应该是底下能够提供资源的具体的所有的Resource Provider(对于计算资源来说,就是所有的计算节点),而不是整个cell,也就是说所有cell中的资源scheduler都可以看到,而子cell就负责创建就好了。因此,在super conductor中,需要做一些transfer的事情,这样也就不必在像cell v1那样,在子cell里还得搞个scheduler去做调度。
- 通过Placement获取可用的备选资源,参考Placement Allocation Requests的实现。 在Ocata版本时,Resource Providers - Scheduler Filters in DB这个BP就已经在调度前加了一步,获取备选节点。从BP的标题就可以看出,设计者想通过Placement服务提供的新的一套机制,来做过滤。原因是之前的调度需要在scheduler维护每一个compute节点的hoststate信息,然后调度的时候,再一个个去查,这太低效了,尤其是在计算节点数目比较多的时候。因此,增加了一个“预过滤”的流程,通过向Placement查询,Placement服务直接通过SQL去查一把,把满足条件(比如CPU充足、RAM充足等)先获取到。 而原来获取备选节点的时候,只支持获取单一的Resource Provider,这个BP增强了获取备选资源的能力,用于后续支持更复杂的请求,比如共享资源、嵌套资源的Provider查询。后面,Placement还会陆续支持更多的请求,比如对一些非存量不可计数的资源的支持。这样留给后面Filter&Weight的压力就小一些了,再往后,会不会完全取代Filter呢?我想,现有的各种过滤都可以通过Placement支持后,完全有可能的。
- Scheduler通过Placement来claim资源。参考Scheduler claiming resources to the Placement API的实现。 在最早的时候,claim资源是由compute来做的,现在相当于提前到scheduler去搞了。有什么好处呢?我们先看看原来的问题: 调度时刻和真正的去compute节点去claim资源的时刻之间是由一段时间的,在资源不是那么充足的环境,就会造成在scheduler调度的时候,资源还没刷新,所以调度时候成功了,但是真正下来的时候,才发现compute实际已经没有资源了,然后又“跨越半个地球”去做重调度,无形地增加了系统的负载。 而且增加了创建的时长(哦,哪怕创建失败呢?),你想想,用户创了那么久的虚拟机,最后你告诉我调度失败了,用户不太能忍。 所以这个BP就把Claim资源放在调度处了,我上一个调度请求处理完,马上就告诉placement,这资源老子用了,其他人不要动了。OK,世界终于清净了,能拿到资源的拿到了,拿不到资源的马上也知道自己拿不到了,大大增强了调度的用户体验。
2.4 Placement
恩,在调度的时候,已经介绍过这个服务了,在虚拟机创建的流程中,比较常用的接口就是获取备选资源和claim资源。 Placement目标很宏伟,大致的作用就是:资源我来管,要资源问我要,用了资源告诉我。后面准备用一篇文章整体介绍一下Placement。(yep,这个Flag我立下了,会写的)
service的详细信息主要包括如下几项: binary, host, zone, status, state 其中: binary,可以理解为service的名称,类似于nova-compute; host是service所在的主机名称; zone是service所属的AZ,其实就是service所在的主机所属的aggregate,只是aggregate的概念不对外呈现,所以用户看到的是AZ。其实,在Nova内部,AZ是AG的metadata而已。
zone的确定,涉及到两个配置项,对于非计算节点,zone的名称依赖于配置项internal_service_availability_zone(默认是internal);
对于计算节点,如果不属于任何AG,或者所属的AG没有AZ的metadata信息,默认的zone依赖于配置项default_availability_zone(默认是nova)。
status是服务disable属性的体现,该属性可以直接通过API修改;
state是服务真实的状态,是通过servicegroup api获取。每个服务在启动时会加入servicegroup,以db后端为例,会在服务中启动定时器,更新service表中的report_count的值,同时也会刷新更新时间,后续会根据这个更新时间确定服务的死活;
当然,查询service信息也支持过滤条件,比如: 1、查询某个host相关的service; 2、按binary名称查询service;
其实Nova中没有host这个独立的资源(数据库对象),但是Nova却有针对host的API操作,其实,在内部实现中,就是通过前面的service信息,间接组装返回host信息。
租户:配额
与此同时,虚拟机state或task_state发生变化时,也会向外部发送通知。
前提是配置项notify_on_state_change要配置为vm_state或vm_and_task_state。
Nova中的虚拟机每个操作(启动、停止、暂停、恢复等等),都会在db中保存相关的操作记录,给用户提供查询。利用这个功能,用户对自己的虚拟机整个生命周期的过程和状态都会了如指掌,便于用户的管理。参见这里。示例如下:
在内部实现中,nova-api层会记录action开始的记录,在nova-compute层,则会添加event开始和结束的信息,action和event根据request id(一次消息请求的标识)关联。
- 先说通知,虚拟机操作异常时,一般都会发送error通知,通知中包含异常的函数名称、异常时函数的参数以及异常信息。
- 再说db,虚拟机操作异常时,无论是在conductor, scheduler还是compute层,除了会发送通知外,还会记录异常信息到数据库(
instance_faults表),当查询虚拟机信息时,会返回虚拟机的异常信息。
一个hypervisor,是创建虚拟机能够调度到的最小单元。
api.py提供对外访问的接口,可以从这开始入手跟踪各个功能实现。rpcapi.py封装RPC请求调用,大多数是异步调用。manager.py各种RPC调用的实现,基本和rpcapi.py中调用的名称一一对应。
此外还有一点,Openstack的目录结构是根据功能划分的,比如Nova中compute目录不一定都是在nova-compute节点上运行,而是所有和虚拟机创建相关的功能都在这里。
从配置文件可以明显的看出,nova-api对应的文件是nova/cmd/api.py的main()函数:
vm_state
power_state
task_state
_record_action_start notify_about_instance_action elevated
@startuml
title: 创建虚拟机
participant "API" as api
note left of api
nova/api/openstack/compute/servers.py
end note
participant "Scheduler" as sch
database "Database" as db #Green
participant "Condutor(super)" as pconductor
participant "Placement" as placement
box "internal service"
participant "Compute" as compute
participant "Libvirt" as virt
end box
participant "Conductor(cell)" as ccondutor
participant "Neutron" as neutron
participant "Cinder" as cinder
participant "Glance" as glance
autonumber "<b> [00]"
[-> api++ : 创建虚拟机
api -> api : validate schema
api -> api : get context
api -> api : get server_dict
api -> api : gen create_kwargs
api -> api : policy check
api -> api : provision instance
api -> glance : 获取镜像信息
api -> api : policy校验
api -> api : 配额校验
api -> api : 添加Group
hnote left #FFAAAA
vm_state: Building
task_state: Scheduling
end note
api -> db : 创建instance
db -> api : create success
[<- api : return 202
deactivate api
api -> pconductor ++: schedule & build
pconductor -> sch : select_destination
sch -> placement : get allocation candidates
placement -> sch : alloc_reqs.provider_summarys
sch -> sch : Filter & weighter
sch -> placement : claim Resources
placement -> sch : hello
sch -> pconductor : return host
pconductor -> pconductor : in target cell DB中创建instance
pconductor -> pconductor : 配额校验 recheck
pconductor -> pconductor : 刷新instance cell 信息
pconductor -> pconductor : 删除build request()
pconductor -> compute : 在指定cell中创建虚拟机
hnote left #FFAAAA
vm_state: Building
task_state: None
end note
compute -> neutron : 创建网络
hnote left #FFAAAA
vm_state: Building
task_state: Networking
end note
compute -> cinder : 构建块设备
hnote left #FFAAAA
vm_state: Building
task_state: Block Device Mapping
end note
compute -> compute : spawn()
hnote left #FFAAAA
vm_state: Building
task_state: Spawning
end note
compute -> glance : 下载镜像
compute -> compute : 生成xml
compute -> compute : 刷新虚拟机状态
hnote left #FFAAAA
vm_state: Building
task_state: None
end note
@enduml
@startuml
title: Lock虚拟机
participant "API" as api
database "Database" as db #Green
autonumber "<b> [00]"
[-> api : lock
api -> api : get_context
api -> api : authorize action [lock] policy
api -> db : get instance by id
db -> api : done
api -> api : check policy
api -> db : instance.locked = True\n locked_by=owner or admin\n record locked reason
db -> api : done
[<- api : response
@enduml
@startuml
title: Pause虚拟机
participant "API" as api
database "Database" as db #Green
box "internal service"
participant "Compute" as compute
participant "Libvirt" as virt
end box
autonumber "<b> [00]"
[-> api++ : pause instance
api -> api : authorize context
api -> db++ : get instance by uuid
return done
api -> api : check policy
api -> api : check instance lock
api -> api : check instance cell
api -> api : ensure instance state is ACTIVE
api -> db++ : task_state = PAUSING
return done
api -> api : record pause action
api -> compute++ : pause_instance
compute -> compute : notify : pause.start
compute -> virt++ : pause
virt -> virt : get domain
virt -> virt : domain.suspend()
return done
compute -> db++ : vm_state = PAUSE\n task_state = None
return done
compute -> compute : notify: pause.end
[<- api : response
@enduml
@startuml
title: Rename虚拟机
participant "API" as api
database "Database" as db #Green
autonumber "<b> [00]"
[-> api : update name
activate api
api -> api : validate schema
api -> api : get context
api -> api : authorize [update] policy
api -> api : get update_dict["display_name"]
api -> db++ : get server by id
return done
api -> db : update(update_dict)
db -> db : save
[<- api : responee
@enduml
@startuml
title: Suspend虚拟机
participant "API" as api
database "Database" as db #Green
box "internal service"
participant "Compute" as compute
participant "Libvirt" as virt
end box
autonumber "<b> [00]"
[-> api++ : suspend instance
api -> api : authorize context
api -> db++ : get instance by uuid
return done
api -> api : check policy
api -> api : check instance lock
api -> api : check instance cell
api -> api : ensure instance state is ACTIVE
api -> db++ : task_state = SUSPANDING
return done
api -> api : record action : suspand
api -> compute++ : suspand_instance
compute -> compute : notify : suspand.start
compute -> virt++ : suspand
virt -> virt : get instance guest
virt -> virt : detach pci device
virt -> virt : detach sriow ports
virt -> virt : guest.save_memory_state()
return done
compute -> db++ : vm_state = SUSPENDED\n task_state = None
return done
compute -> compute : notify: suspend.end
[<- api : response
@enduml
@startuml
hide empty description
[*] --> State1
State1 --> [*]
vm_state:powering\n task_state:good\n nihao
State1 : this is another string
State1 -> State2
State2 --> [*]
@enduml
@startuml
title: Unlock虚拟机
participant "API" as api
database "Database" as db #Green
autonumber "<b> [00]"
[-> api : lock
api -> api : get_context
api -> api : authorize action [unlock] policy
api -> db : get instance by id
db -> api : done
api -> api : check policy
api -> db : query instance.locked
db -> api : done
api -> db : instance.locked = False\n locked_by=None\n clear locked reason
db -> api : done
[<- api : response
@enduml
@startuml
title: Unpause虚拟机
participant "API" as api
database "Database" as db #Green
box "internal service"
participant "Compute" as compute
participant "Libvirt" as virt
end box
autonumber "<b> [00]"
[-> api++ : unpause instance
api -> api : authorize context
api -> db++ : get instance by uuid
return done
api -> api : check policy
api -> api : check instance lock
api -> api : check instance cell
api -> api : ensure instance state is PAUSED
api -> db++ : task_state = UNPAUSING
return done
api -> api : record action : unpause
api -> compute++ : unpause_instance
compute -> compute : notify : unpause.start
compute -> virt++ : unpause
virt -> virt : get domain
virt -> virt : domain.resume()
return done
compute -> db++ : vm_state = ACTIVE\n task_state = None
return done
compute -> compute : notify: unpause.end
[<- api : response
@enduml