简介
相比p2p即点对点通信,集合通信的参与方可以大于2个,同时在通信中引入同步点,所有代码在达到同步点后才能继续执行后续的代码。 通常包含如下通信类型:
- Broadcast
- Scatter
- Gather
- AllGather
- Reduce
- AllReduce
将用mpi4py(mpi的一个python包装库)代码加深对集合通信的理解,c语言的mpi代码可以参考mpitutorial/tutorials/run.py at gh-pages · mpitutorial/mpitutorial,也将提供一些torch进行集合通信的示例。
因此,需要首先安装依赖包
apt-get update && apt-get install mpich
mpirun --version
pip install mpi4py
pip install torch
执行环境
常见的分布式程序需要一个launcher,例如mpi、torchrun、ray等,这里会使用两种
- mpiexec
- torchrun
主要使用mpiexec
示例代码如下:
# torch_mpi_send.py
import os
import argparse
import torch
import torch.distributed as dist
LOCAL_RANK = 0
WORLD_SIZE = 0
WORLD_RANK = 0
def init_global_vars(frontend):
global LOCAL_RANK
global WORLD_SIZE
global WORLD_RANK
env_vars = os.environ
if frontend == "mpi":
# Environment variables set by mpiexec
LOCAL_RANK = int(os.environ['OMPI_COMM_WORLD_LOCAL_RANK'])
WORLD_SIZE = int(os.environ['OMPI_COMM_WORLD_SIZE'])
WORLD_RANK = int(os.environ['OMPI_COMM_WORLD_RANK'])
else:
# Environment variables set by torch.distributed.launch
LOCAL_RANK = int(os.environ['LOCAL_RANK'])
WORLD_SIZE = int(os.environ['WORLD_SIZE'])
WORLD_RANK = int(os.environ['RANK'])
def run(backend):
tensor = torch.zeros(10,10)
# Need to put tensor on a GPU device for nccl backend
if backend == 'nccl':
# device = torch.device("cuda:{}".format(LOCAL_RANK))
device = torch.device("cuda:{}".format(0))
tensor = tensor.to(device)
if WORLD_RANK == 0:
for rank_recv in range(1, WORLD_SIZE):
tensor = torch.ones(10,10)
dist.send(tensor=tensor, dst=rank_recv)
print('worker_{} sent data to Rank {}\n'.format(0, rank_recv))
else:
dist.recv(tensor=tensor, src=0)
print(f'worker_{WORLD_RANK} has received data {tensor.cpu()} from rank 0\n')
def init_processes(frontend, backend):
init_global_vars(frontend=frontend)
print(f"local rank {LOCAL_RANK} world size {WORLD_SIZE} world rank {WORLD_RANK}")
dist.init_process_group(backend, rank=WORLD_RANK, world_size=WORLD_SIZE)
run(backend)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--local-rank", type=int, help="Local rank. Necessary for using the torch.distributed.launch utility.")
parser.add_argument("--backend", type=str, default="nccl", choices=['nccl', 'gloo'])
parser.add_argument("--frontend", type=str, default="mpi", choices=['mpi', 'torch'])
args = parser.parse_args()
init_processes(frontend=args.frontend, backend=args.backend)
mpi
用mpi启动一个pytorch的分布式训练程序,特点是只需要在master节点执行即可,跨节点时候需要配置节点之间ssh互信免密访问。
如果
--backend nccl,需要环境上至少有两块GPU卡
mpirun --allow-run-as-root -n 2 --use-hwthread-cpus \
-H localhost:2 \
-x MASTER_ADDR=localhost \
-x MASTER_PORT=1234 \
-x PATH \
-bind-to none -map-by slot \
-mca pml ob1 -mca btl ^openib \
python torch_mpi_send.py --backend gloo --frontend=mpi
输出如下
local rank 1 world size 2 world rank 1
[W socket.cpp:697] [c10d] The client socket has failed to connect to [localhost]:1234 (errno: 99 - Cannot assign requested address).
local rank 0 world size 2 world rank 0
worker_1 has received data tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]]) from rank 0
worker_0 sent data to Rank 1
torchrun
torchrun跨节点时需要在多节点上执行命令
torchrun \
--nproc_per_node=2 --nnodes=1 --node_rank=0 \
--master_addr=localhost --master_port=1234 \
torch_mpi_send.py \
--backend=gloo --frontend torch
输出如下
local rank 0 world size 2 world rank 0
local rank 1 world size 2 world rank 1
worker_0 sent data to Rank 1
worker_1 has received data tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]]) from rank 0
Broadcast
广播将一个进程中的数据发送到所有其他进程。通常用于将一个进程的消息或数据复制到所有参与者。
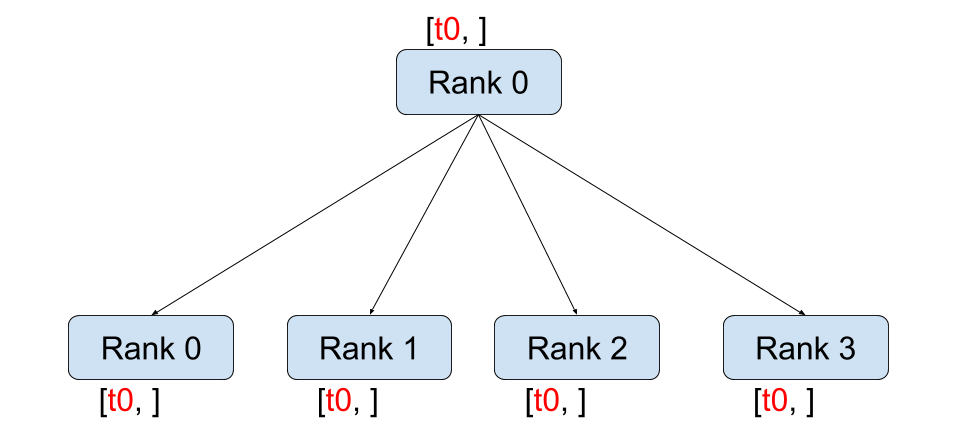
- mpi4py实现
# broadcast.py
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0:
data = {'key1' : [7, 2.72, 2+3j],
'key2' : ( 'abc', 'xyz')}
else:
data = None
data = comm.bcast(data, root=0)
print(f"rank {rank} data is {data}")
mpiexec --allow-run-as-root -n 4 --use-hwthread-cpus --oversubscribe python broadcast.py
# rank 0 data is {'key1': [7, 2.72, (2+3j)], 'key2': ('abc', 'xyz')}
# rank 1 data is {'key1': [7, 2.72, (2+3j)], 'key2': ('abc', 'xyz')}
# rank 2 data is {'key1': [7, 2.72, (2+3j)], 'key2': ('abc', 'xyz')}
# rank 3 data is {'key1': [7, 2.72, (2+3j)], 'key2': ('abc', 'xyz')}
- pytorch实现
#!/usr/bin/env python
import os
import torch
import torch.distributed as dist
LOCAL_RANK = int(os.environ['LOCAL_RANK'])
WORLD_SIZE = int(os.environ['WORLD_SIZE'])
WORLD_RANK = int(os.environ['RANK'])
def run_broadcast(rank, size):
# create a group with all processors
group = dist.new_group(list(range(size)))
if rank == 0:
tensor = torch.tensor([rank], dtype=torch.float32)
else:
tensor = torch.empty(1)
# sending all tensors to the others
dist.broadcast(tensor, src=0, group=group)
# all ranks will have tensor([0.]) from rank 0
print(f"[{rank}] data = {tensor}")
def init_process(backend='gloo'):
dist.init_process_group(backend, init_method="file:///tmp/sharedfile", rank=WORLD_RANK, world_size=WORLD_SIZE)
run_broadcast(WORLD_RANK, WORLD_SIZE)
init_process()
!torchrun \
--nproc_per_node=4 --nnodes=1 --node_rank=0 \
torch_broadcast.py
所有rank都收到了同样的数据
[3] data = tensor([0.])
[1] data = tensor([0.])
[2] data = tensor([0.])
[0] data = tensor([0.])
Scatter
Scatter将一个进程中的数据分发到多个进程中。源进程将数据分成多个部分,并将每部分发送到不同的目标进程。
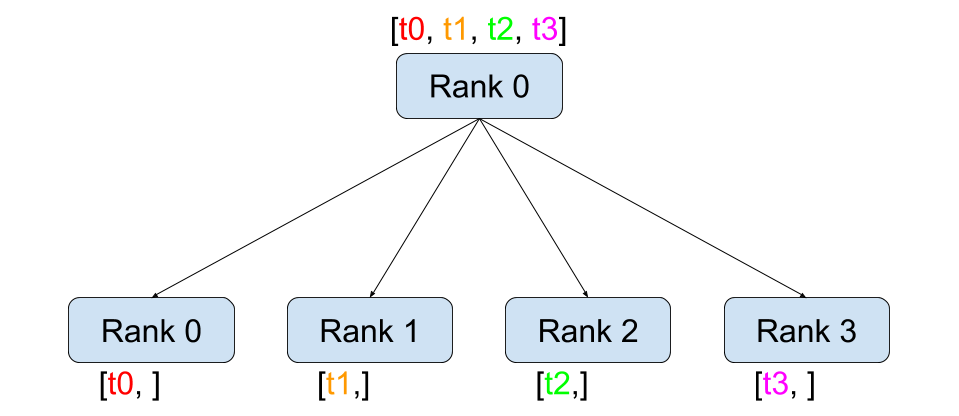
- mpi4py实现
# scatter.py
from mpi4py import MPI
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
if rank == 0:
data = [list(range(i+2)) for i in range(size)]
else:
data = None
data = comm.scatter(data, root=0)
print(f"rank {rank} data is {data}")
rank 0 上数据是
[[0, 1], [0, 1 ,2], [0, 1, 2, 3], [0, 1, 2, 3, 4]],列表共两个元素,分发到两个rank上,rank0获得第一个元素,rank1获得第二个元素, 以此类推。--use-hwthread-cpus --oversubscribe是因为执行环境只有2核的cpu,如果有更多的cpu,可以去掉这两个参数。
mpiexec --allow-run-as-root -n 2 --use-hwthread-cpus --oversubscribe python scatter.py
rank 2 data is [0, 1, 2, 3]
rank 1 data is [0, 1, 2]
rank 0 data is [0, 1]
rank 3 data is [0, 1, 2, 3, 4]
mpi4py还支持numpy对象,具体可以参考使用文档Tutorial — MPI for Python 4.0.0 documentation
- pytorch实现
#!/usr/bin/env python
import os
import torch
import torch.distributed as dist
LOCAL_RANK = int(os.environ['LOCAL_RANK'])
WORLD_SIZE = int(os.environ['WORLD_SIZE'])
WORLD_RANK = int(os.environ['RANK'])
def run_scatter(rank, size):
# create a group with all processors
group = dist.new_group(list(range(size)))
# sending all tensors from rank 0 to the others
tensor = torch.empty(1)
if rank == 0:
tensor_list = [torch.tensor([i + 1], dtype=torch.float32) for i in range(size)]
# tensor_list = [tensor(1), tensor(2), tensor(3), tensor(4)]
dist.scatter(tensor, scatter_list=tensor_list, src=0, group=group)
else:
dist.scatter(tensor, scatter_list=[], src=0, group=group)
# each rank will have a tensor with their rank number
dist.barrier()
print(f'\nRank {rank} received data {tensor}')
def init_process(backend='gloo'):
dist.init_process_group(backend, init_method="file:///tmp/sharedfile", rank=WORLD_RANK, world_size=WORLD_SIZE)
run_scatter(WORLD_RANK, WORLD_SIZE)
init_process()
torchrun \
--nproc_per_node=4 --nnodes=1 --node_rank=0 \
torch_scatter.py
Rank 2 received data tensor([3.])
Rank 0 received data tensor([1.])
Rank 1 received data tensor([2.])
Rank 3 received data tensor([4.])
Gather
Gather操作是将多个进程中的数据汇聚到一个进程中。每个参与进程将其数据发送到指定的根进程,根进程将所有数据整合在一起。
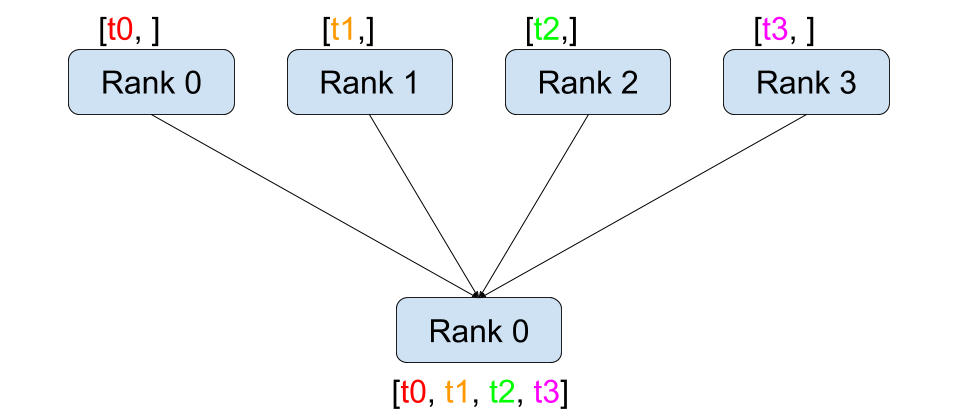
- mpi4py实现
# gather.py
from mpi4py import MPI
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
if rank == 0:
data = [list(range(i+2)) for i in range(size)]
else:
data = None
data = comm.scatter(data, root=0)
print(f"rank {rank} data is {data}")
- pytorch实现
#!/usr/bin/env python
import os
import torch
import torch.distributed as dist
LOCAL_RANK = int(os.environ['LOCAL_RANK'])
WORLD_SIZE = int(os.environ['WORLD_SIZE'])
WORLD_RANK = int(os.environ['RANK'])
def run_gather(rank, size):
# create a group with all processors
group = dist.new_group(list(range(size)))
tensor = torch.tensor([rank], dtype=torch.float32)
# sending all tensors from rank 0 to the others
if rank == 0:
# create an empty list we will use to hold the gathered values
tensor_list = [torch.empty(1) for i in range(size)]
dist.gather(tensor, gather_list=tensor_list, dst=0, group=group)
else:
dist.gather(tensor, gather_list=[], dst=0, group=group)
# only rank 0 will have the tensors from the other processed
# [tensor([0.]), tensor([1.]), tensor([2.]), tensor([3.])]
if rank == 0:
print(f"[{rank}] data = {tensor_list}")
def init_process(backend='gloo'):
dist.init_process_group(backend, init_method="file:///tmp/sharedfile", rank=WORLD_RANK, world_size=WORLD_SIZE)
run_gather(WORLD_RANK, WORLD_SIZE)
init_process()
输出为
[0] data = [tensor([0.]), tensor([1.]), tensor([2.]), tensor([3.])]
All-Gather
All Gather 操作是将所有进程中的数据汇聚到每个进程中。每个进程不仅接收来自根进程的数据,还接收来自其他所有进程的数据。
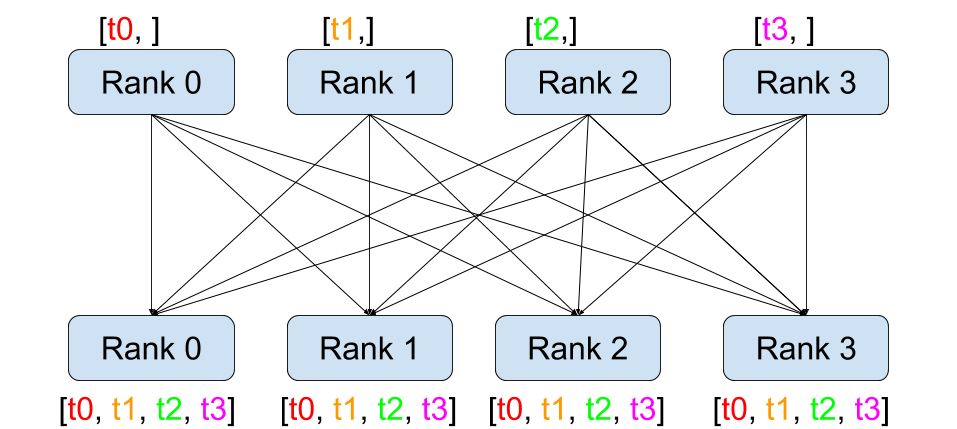
- mpi4py实现
# allgather.py
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
# 每个进程生成一个数据
data = np.array(rank + 1) # 每个进程的数据为其 rank + 1
gathered_data = np.zeros(size, dtype=int)
# 执行 AllGather 操作
comm.Allgather(data, gathered_data)
print(f"Rank {rank} gathered data: {gathered_data}")
mpiexec --allow-run-as-root -n 4 --use-hwthread-cpus --oversubscribe python mpi_allgather.py
Rank 1 gathered data: [1 2 3 4]
Rank 3 gathered data: [1 2 3 4]
Rank 0 gathered data: [1 2 3 4]
Rank 2 gathered data: [1 2 3 4]
- pytorch实现
#!/usr/bin/env python
import os
import torch
import torch.distributed as dist
LOCAL_RANK = int(os.environ['LOCAL_RANK'])
WORLD_SIZE = int(os.environ['WORLD_SIZE'])
WORLD_RANK = int(os.environ['RANK'])
def run_all_gather(rank, size):
# create a group with all processors
group = dist.new_group(list(range(size)))
tensor = torch.tensor([rank], dtype=torch.float32)
# create an empty list we will use to hold the gathered values
tensor_list = [torch.empty(1) for i in range(size)]
# sending all tensors to the others
dist.all_gather(tensor_list, tensor, group=group)
# all ranks will have [tensor([0.]), tensor([1.]), tensor([2.]), tensor([3.])]
print(f"[{rank}] data = {tensor_list}")
def init_process(backend='gloo'):
dist.init_process_group(backend, init_method="file:///tmp/sharedfile", rank=WORLD_RANK, world_size=WORLD_SIZE)
run_all_gather(WORLD_RANK, WORLD_SIZE)
init_process()
Reduce
Reduce操作将多个进程中的数据通过某种运算(如求和、取最大值等)整合成一个结果,并将该结果发送到一个指定的根进程

- mpi4py实现
# reduce.py
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
# 每个进程生成一个数据
data = np.array(rank + 1) # 每个进程的数据为其 rank + 1
# 只有根进程接收结果
if rank == 0:
result = np.zeros(1, dtype=int)
else:
result = None
# 执行 Reduce 操作
comm.Reduce(data, result, op=MPI.SUM, root=0)
if rank == 0:
print(f"Result after Reduce: {result[0]}")
mpiexec --allow-run-as-root -n 4 --use-hwthread-cpus --oversubscribe python mpi_reduce.py
# Result after Reduce: 10
- pytorch实现
#!/usr/bin/env python
import os
import torch
import torch.distributed as dist
LOCAL_RANK = int(os.environ['LOCAL_RANK'])
WORLD_SIZE = int(os.environ['WORLD_SIZE'])
WORLD_RANK = int(os.environ['RANK'])
def run_reduce(rank, size):
# create a group with all processors
group = dist.new_group(list(range(size)))
tensor = torch.ones(1)
# sending all tensors to rank 0 and sum them
dist.reduce(tensor, dst=0, op=dist.ReduceOp.SUM, group=group)
# can be dist.ReduceOp.PRODUCT, dist.ReduceOp.MAX, dist.ReduceOp.MIN
# only rank 0 will have four
print(f"[{rank}] data = {tensor[0]}")
def init_process(backend='gloo'):
dist.init_process_group(backend, init_method="file:///tmp/sharedfile", rank=WORLD_RANK, world_size=WORLD_SIZE)
run_reduce(WORLD_RANK, WORLD_SIZE)
init_process()
All-Reduce
All Reduce操作是将所有进程中的数据进行归约运算,并将结果发送到所有进程。每个进程都能获得归约后的结果。
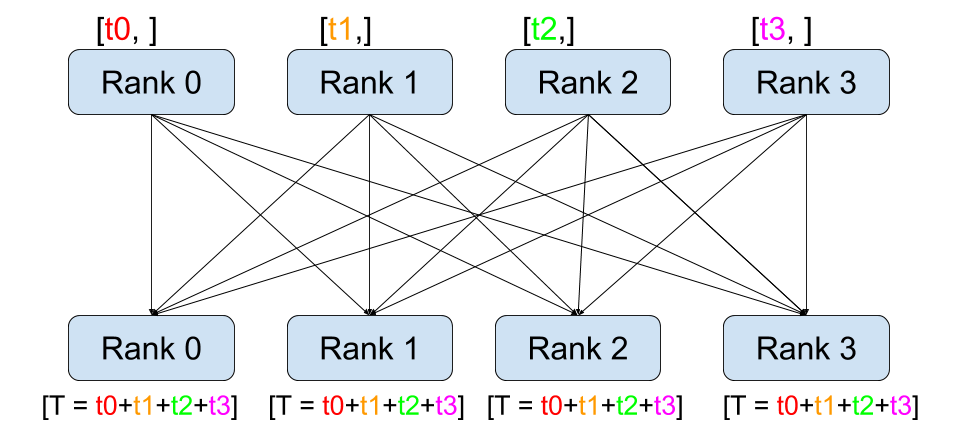
- mpi4py实现
# allreduce.py
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
# 每个进程生成一个数据
data = np.array(rank + 1) # 每个进程的数据为其 rank + 1
# 执行 AllReduce 操作
result = np.zeros(1, dtype=int)
comm.Allreduce(data, result, op=MPI.SUM)
print(f"Rank {rank} has result after AllReduce: {result[0]}")
mpiexec --allow-run-as-root -n 4 --use-hwthread-cpus --oversubscribe python all_reduce.py
Rank 1 has result after AllReduce: 10
Rank 3 has result after AllReduce: 10
Rank 0 has result after AllReduce: 10
Rank 2 has result after AllReduce: 10
- Pytorch实现
#!/usr/bin/env python
# torch_all_reduce.py
import os
import torch
import torch.distributed as dist
# Environment variables set by torch.distributed.launch or torchrun
LOCAL_RANK = int(os.environ['LOCAL_RANK'])
WORLD_SIZE = int(os.environ['WORLD_SIZE'])
WORLD_RANK = int(os.environ['RANK'])
""" All-Reduce example."""
def run(rank, size):
""" Simple collective communication. """
group = dist.new_group([0, 1, 2, 3])
tensor = torch.ones(2,3)
dist.all_reduce(tensor, op=dist.ReduceOp.SUM, group=group)
dist.barrier(group)
print(f'\nRank {rank} has data {tensor}')
def init_process(backend='gloo'):
""" Initialize the distributed environment. """
dist.init_process_group(backend, init_method="file:///tmp/sharedfile", rank=WORLD_RANK, world_size=WORLD_SIZE)
run(WORLD_RANK, WORLD_SIZE)
init_process()
torchrun \
--nproc_per_node=4 --nnodes=1 --node_rank=0 \
torch_all_reduce.py
Rank 0 has data tensor([[4., 4., 4.],
[4., 4., 4.]])
Rank 1 has data tensor([[4., 4., 4.],
[4., 4., 4.]])
Rank 3 has data tensor([[4., 4., 4.],
[4., 4., 4.]])
Rank 2 has data tensor([[4., 4., 4.],
[4., 4., 4.]])
参考
Writing Distributed Applications with PyTorch — PyTorch Tutorials 2.4.0+cu121 documentation Tutorial — MPI for Python 4.0.0 documentation
Collective Communication in Distributed Systems with PyTorch
mpitutorial/mpitutorial: MPI programming lessons in C and executable code examples
MPI 广播以及集体(collective)通信 · MPI Tutorial PyTorch分布式训练详解教程 scatter, gather & isend, irecv & all_reduce & DDP - 天靖居士 - 博客园